Reducing the number of input variables for a predictive model is referred to as dimensionality reduction.
Fewer input variables can result in a simpler predictive model that may have better performance when making predictions on new data.
Perhaps the more popular technique for dimensionality reduction in machine learning is Singular Value Decomposition, or SVD for short. This is a technique that comes from the field of linear algebra and can be used as a data preparation technique to create a projection of a sparse dataset prior to fitting a model.
In this tutorial, you will discover how to use SVD for dimensionality reduction when developing predictive models.
After completing this tutorial, you will know:
- Dimensionality reduction involves reducing the number of input variables or columns in modeling data.
- SVD is a technique from linear algebra that can be used to automatically perform dimensionality reduction.
- How to evaluate predictive models that use an SVD projection as input and make predictions with new raw data.
Let’s get started.

Singular Value Decomposition for Dimensionality Reduction in Python
Photo by Kimberly Vardeman, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Dimensionality Reduction and SVD
- SVD Scikit-Learn API
- Worked Example of SVD for Dimensionality
Dimensionality Reduction and SVD
Dimensionality reduction refers to reducing the number of input variables for a dataset.
If your data is represented using rows and columns, such as in a spreadsheet, then the input variables are the columns that are fed as input to a model to predict the target variable. Input variables are also called features.
We can consider the columns of data representing dimensions on an n-dimensional feature space and the rows of data as points in that space. This is a useful geometric interpretation of a dataset.
In a dataset with k numeric attributes, you can visualize the data as a cloud of points in k-dimensional space …
— Page 305, Data Mining: Practical Machine Learning Tools and Techniques, 4th edition, 2016.
Having a large number of dimensions in the feature space can mean that the volume of that space is very large, and in turn, the points that we have in that space (rows of data) often represent a small and non-representative sample.
This can dramatically impact the performance of machine learning algorithms fit on data with many input features, generally referred to as the “curse of dimensionality.”
Therefore, it is often desirable to reduce the number of input features. This reduces the number of dimensions of the feature space, hence the name “dimensionality reduction.”
A popular approach to dimensionality reduction is to use techniques from the field of linear algebra. This is often called “feature projection” and the algorithms used are referred to as “projection methods.”
Projection methods seek to reduce the number of dimensions in the feature space whilst also preserving the most important structure or relationships between the variables observed in the data.
When dealing with high dimensional data, it is often useful to reduce the dimensionality by projecting the data to a lower dimensional subspace which captures the “essence” of the data. This is called dimensionality reduction.
— Page 11, Machine Learning: A Probabilistic Perspective, 2012.
The resulting dataset, the projection, can then be used as input to train a machine learning model.
In essence, the original features no longer exist and new features are constructed from the available data that are not directly comparable to the original data, e.g. don’t have column names.
Any new data that is fed to the model in the future when making predictions, such as test datasets and new datasets, must also be projected using the same technique.
Singular Value Decomposition, or SVD, might be the most popular technique for dimensionality reduction when data is sparse.
Sparse data refers to rows of data where many of the values are zero. This is often the case in some problem domains like recommender systems where a user has a rating for very few movies or songs in the database and zero ratings for all other cases. Another common example is a bag of words model of a text document, where the document has a count or frequency for some words and most words have a 0 value.
Examples of sparse data appropriate for applying SVD for dimensionality reduction:
- Recommender Systems
- Customer-Product purchases
- User-Song Listen Counts
- User-Movie Ratings
- Text Classification
- One Hot Encoding
- Bag of Words Counts
- TF/IDF
For more on sparse data and sparse matrices generally, see the tutorial:
SVD can be thought of as a projection method where data with m-columns (features) is projected into a subspace with m or fewer columns, whilst retaining the essence of the original data.
The SVD is used widely both in the calculation of other matrix operations, such as matrix inverse, but also as a data reduction method in machine learning.
For more information on how SVD is calculated in detail, see the tutorial:
Now that we are familiar with SVD for dimensionality reduction, let’s look at how we can use this approach with the scikit-learn library.
SVD Scikit-Learn API
We can use SVD to calculate a projection of a dataset and select a number of dimensions or principal components of the projection to use as input to a model.
The scikit-learn library provides the TruncatedSVD class that can be fit on a dataset and used to transform a training dataset and any additional dataset in the future.
For example:
... data = ... svd = TruncatedSVD() svd.fit(data) transformed = svd.transform(data)
The outputs of the SVD can be used as input to train a model.
Perhaps the best approach is to use a Pipeline where the first step is the SVD transform and the next step is the learning algorithm that takes the transformed data as input.
...
# define the pipeline
steps = [('svd', TruncatedSVD()), ('m', LogisticRegression())]
model = Pipeline(steps=steps)
Now that we are familiar with the SVD API, let’s look at a worked example.
Worked Example of SVD for Dimensionality
SVD is typically used on sparse data.
This includes data for a recommender system or a bag of words model for text. If the data is dense, then it is better to use the PCA method.
Nevertheless, for simplicity, we will demonstrate SVD on dense data in this section. You can easily adapt it for your own sparse dataset.
First, we can use the make_classification() function to create a synthetic binary classification problem with 1,000 examples and 20 input features, 15 inputs of which are meaningful.
The complete example is listed below.
# test classification dataset from sklearn.datasets import make_classification # define dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # summarize the dataset print(X.shape, y.shape)
Running the example creates the dataset and summarizes the shape of the input and output components.
(1000, 20) (1000,)
Next, we can use dimensionality reduction on this dataset while fitting a logistic regression model.
We will use a Pipeline where the first step performs the SVD transform and selects the 10 most important dimensions or components, then fits a logistic regression model on these features. We don’t need to normalize the variables on this dataset, as all variables have the same scale by design.
The pipeline will be evaluated using repeated stratified cross-validation with three repeats and 10 folds per repeat. Performance is presented as the mean classification accuracy.
The complete example is listed below.
# evaluate svd with logistic regression algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the pipeline
steps = [('svd', TruncatedSVD(n_components=10)), ('m', LogisticRegression())]
model = Pipeline(steps=steps)
# evaluate model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Running the example evaluates the model and reports the classification accuracy.
In this case, we can see that the SVD transform with logistic regression achieved a performance of about 81.4 percent.
Accuracy: 0.814 (0.034)
How do we know that reducing 20 dimensions of input down to 10 is good or the best we can do?
We don’t; 10 was an arbitrary choice.
A better approach is to evaluate the same transform and model with different numbers of input features and choose the number of features (amount of dimensionality reduction) that results in the best average performance.
The example below performs this experiment and summarizes the mean classification accuracy for each configuration.
# compare svd number of components with logistic regression algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,20):
steps = [('svd', TruncatedSVD(n_components=i)), ('m', LogisticRegression())]
models[str(i)] = Pipeline(steps=steps)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.xticks(rotation=45)
pyplot.show()
Running the example first reports the classification accuracy for each number of components or features selected.
We can see a general trend of increased performance as the number of dimensions is increased. On this dataset, the results suggest a trade-off in the number of dimensions vs. the classification accuracy of the model.
Interestingly, we don’t see any improvement beyond 15 components. This matches our definition of the problem where only the first 15 components contain information about the class and the remaining five are redundant.
>1 0.542 (0.046) >2 0.626 (0.050) >3 0.719 (0.053) >4 0.722 (0.052) >5 0.721 (0.054) >6 0.729 (0.045) >7 0.802 (0.034) >8 0.800 (0.040) >9 0.814 (0.037) >10 0.814 (0.034) >11 0.817 (0.037) >12 0.820 (0.038) >13 0.820 (0.036) >14 0.825 (0.036) >15 0.865 (0.027) >16 0.865 (0.027) >17 0.865 (0.027) >18 0.865 (0.027) >19 0.865 (0.027)
A box and whisker plot is created for the distribution of accuracy scores for each configured number of dimensions.
We can see the trend of increasing classification accuracy with the number of components, with a limit at 15.
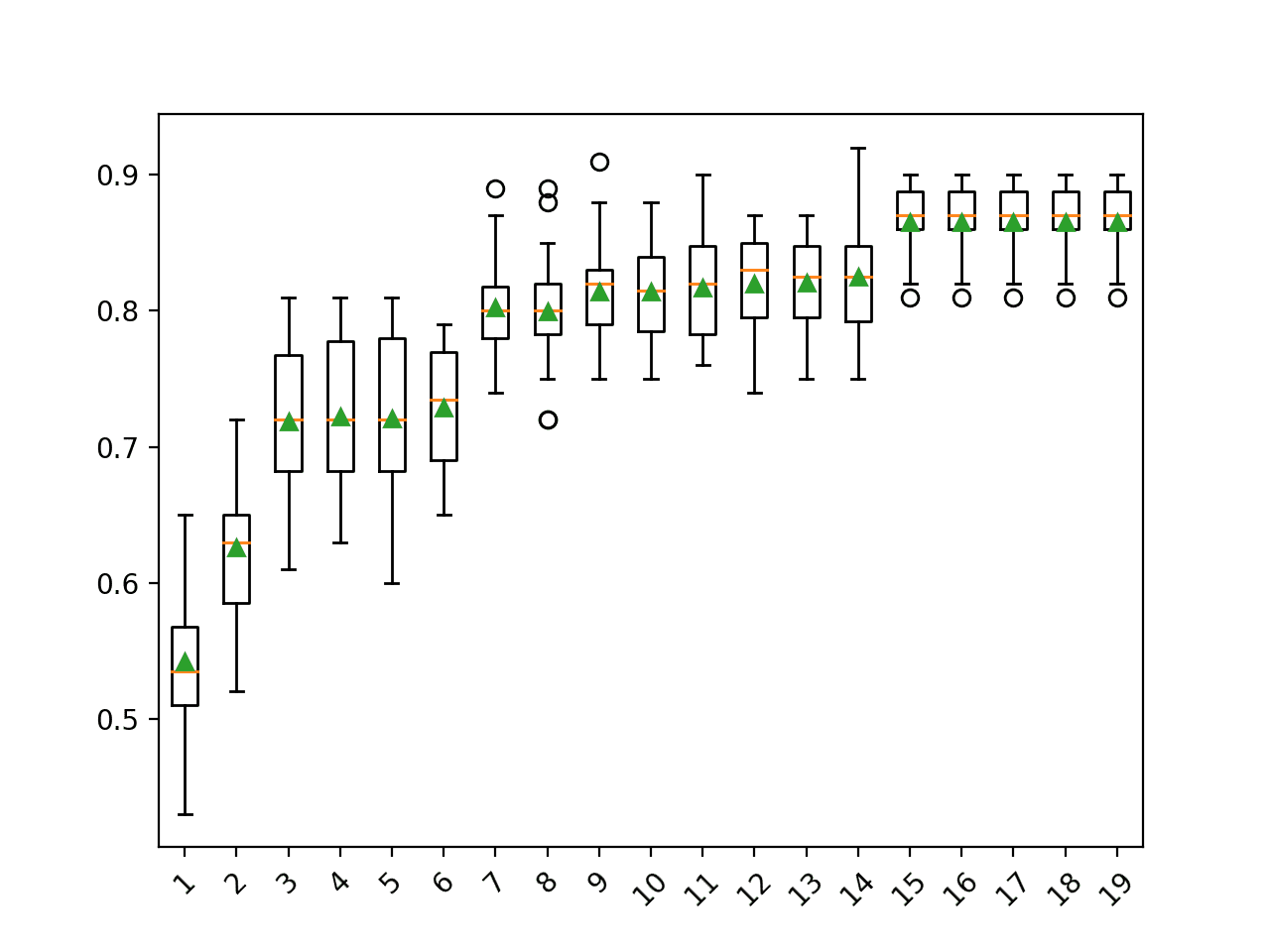
Box Plot of SVD Number of Components vs. Classification Accuracy
We may choose to use an SVD transform and logistic regression model combination as our final model.
This involves fitting the Pipeline on all available data and using the pipeline to make predictions on new data. Importantly, the same transform must be performed on this new data, which is handled automatically via the Pipeline.
The code below provides an example of fitting and using a final model with SVD transforms on new data.
# make predictions using svd with logistic regression
from sklearn.datasets import make_classification
from sklearn.pipeline import Pipeline
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
steps = [('svd', TruncatedSVD(n_components=15)), ('m', LogisticRegression())]
model = Pipeline(steps=steps)
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [[0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]]
yhat = model.predict(row)
print('Predicted Class: %d' % yhat[0])
Running the example fits the Pipeline on all available data and makes a prediction on new data.
Here, the transform uses the 15 most important components from the SVD transform, as we found from testing above.
A new row of data with 20 columns is provided and is automatically transformed to 15 components and fed to the logistic regression model in order to predict the class label.
Predicted Class: 1
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- A Gentle Introduction to Sparse Matrices for Machine Learning
- How to Calculate the SVD from Scratch with Python
Papers
Books
- Machine Learning: A Probabilistic Perspective, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 4th edition, 2016.
- Pattern Recognition and Machine Learning, 2006.
APIs
- Decomposing signals in components (matrix factorization problems), scikit-learn.
- sklearn.decomposition.TruncatedSVD API.
- sklearn.pipeline.Pipeline API.
Articles
- Dimensionality reduction, Wikipedia.
- Curse of dimensionality, Wikipedia.
- Singular value decomposition, Wikipedia.
Summary
In this tutorial, you discovered how to use SVD for dimensionality reduction when developing predictive models.
Specifically, you learned:
- Dimensionality reduction involves reducing the number of input variables or columns in modeling data.
- SVD is a technique from linear algebra that can be used to automatically perform dimensionality reduction.
- How to evaluate predictive models that use an SVD projection as input and make predictions with new raw data.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Singular Value Decomposition for Dimensionality Reduction in Python appeared first on Machine Learning Mastery.
Ai
via https://www.AiUpNow.com
May 10, 2020 at 03:11PM by Jason Brownlee, Khareem Sudlow
